
株式会社jeki Data-Driven Lab データマネジメント部の俊です。
CSVのDB化について、前回記事ではGoogle Cloud StorageとBigQueryのみを用いたシンプルな構成をまとめました。
後編である今回は、より発展的なアーキテクチャについてご紹介します。
この記事を読んでほしい人(再掲)
– CSVをDBに取り込みたい人
– GCPの基礎的なアーキテクチャを知りたい人
アーキテクチャ概要
サービス紹介(再掲)
今回用いるGoogle Cloud Platformのサービスは以下の3つです。
| サービス名 | 役割 | AWSでいうと? |
| Google Cloud Storage | 様々なファイルをクラウドに保存できる オブジェクトストレージサービス | Amazon S3 |
| Google Cloud Functions | 指定したイベントをきっかけに関数を実行する クラウドコンピューティングサービス | AWS Lambda |
| Google Cloud BigQuery | データ分析プロダクトに最適化された データウェアハウスサービス | Amazon Redshift |
個人的な話ではありますが、GCPに触れてこなかった筆者としては前職で使っていたAWSと同様のサービスに置き換えて考えてみると非常にわかりやすかったです。
連携イメージ(一部再掲)
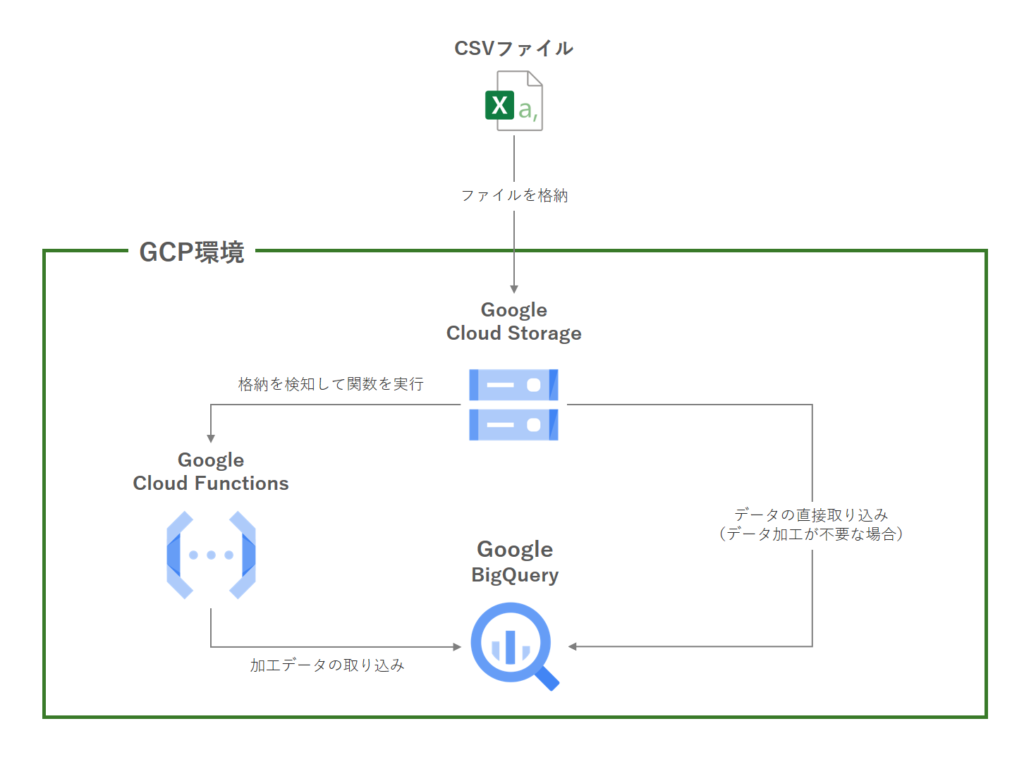
アーキテクチャとしては大きく分けて2パターンあります。
– Cloud Functionsを使わない方法
– Cloud Functionsを使う方法(後編でご紹介)
CSVファイルの中身がすでに整形済みでそのままBigQueryに保存できる場合には、Cloud Functionsは導入不要です。このケースではCloud StorageからBigQueryへ直接データを取り込みます。
一方でCSVデータの整形・加工が必要な場合には、Cloud Functionsを介してデータクレンジングを行ってからBigQueryにデータを取り込みます。データの自動更新にも対応しているため、汎用性が高いことが特徴です。
今回は本題であるCloud Functionsを使う方法についてのご紹介となります。
活用例
– CSVデータを加工して保存したい
– データの更新が頻繁に発生する
– 更新フローを自動化したい
といった状況での活用が想定されます。
Cloud Functionsを用いるとコーディングが必要になるため開発コストがかさみますが、その一方で汎用性が非常に高くなります。
こちらは当社でも頻繁に採用するアーキテクチャです。
お客様のデータを分析するにあたって、当社GCP環境下でデータマートを構築することを目的としてデータのつなぎ込みを行っております。
なお本記事ではコードは全てPython 3にてご紹介いたします。
その他.NET, Go, Java, Node.js, Rubyが使用可能です(2024年6月時点)
取り込み方法
GCS設定
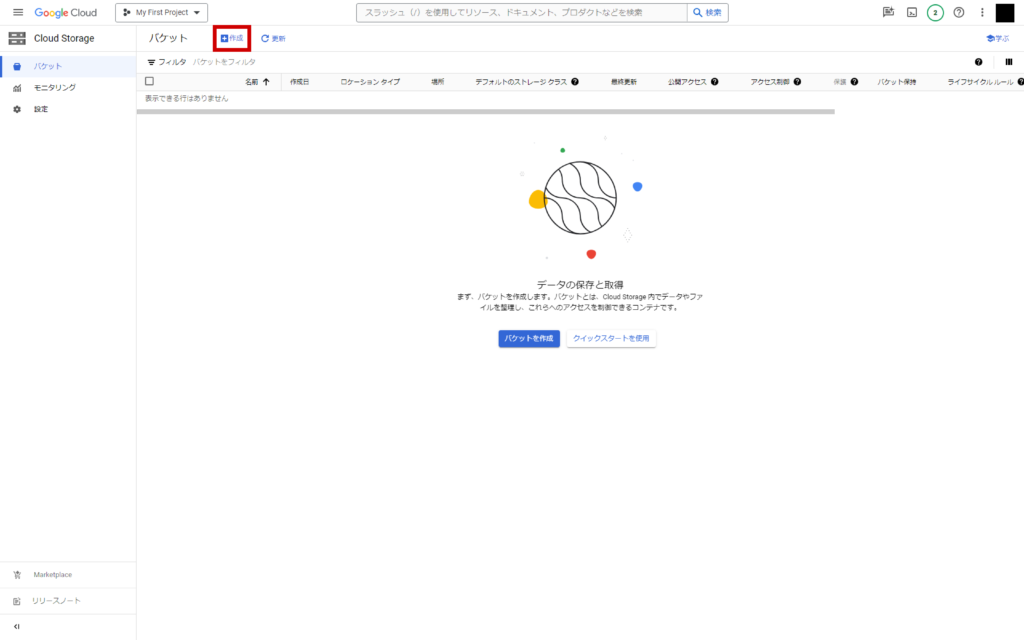
GCSトップページから「作成」をクリック
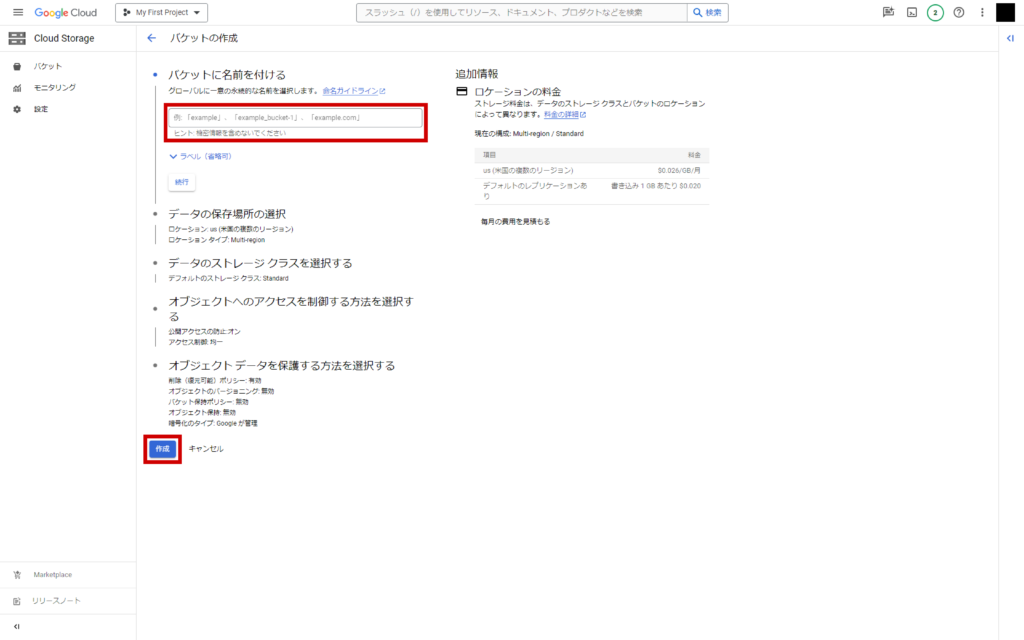
バケットに名前を付けます。以降の設定はデフォルトのままで「作成」をクリック。
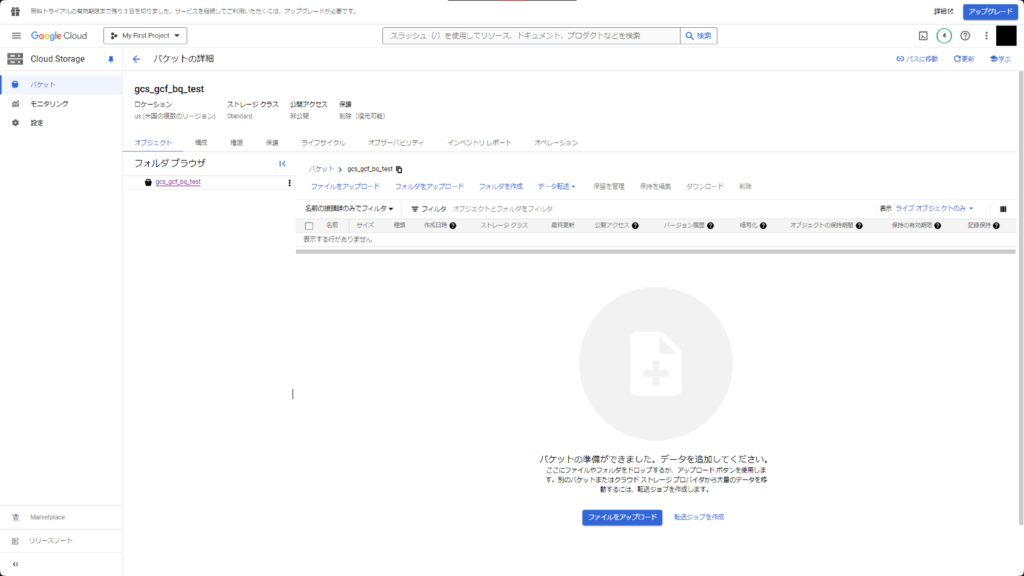
バケットが作成されました。
CSVファイルは後ほどアップロードしますので、先にBigQueryとCloud Functionsの設定を進めます。
BigQueryの設定
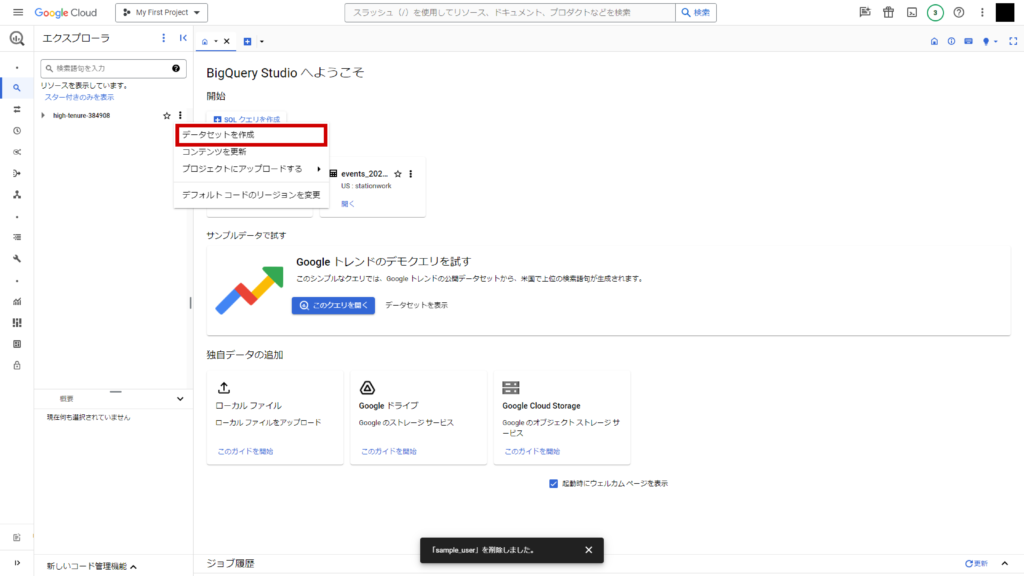
BigQuery コンソールにアクセスします。
任意のプロジェクトIDを選択し、右の三点ボタンから「データセットを作成」をクリック。
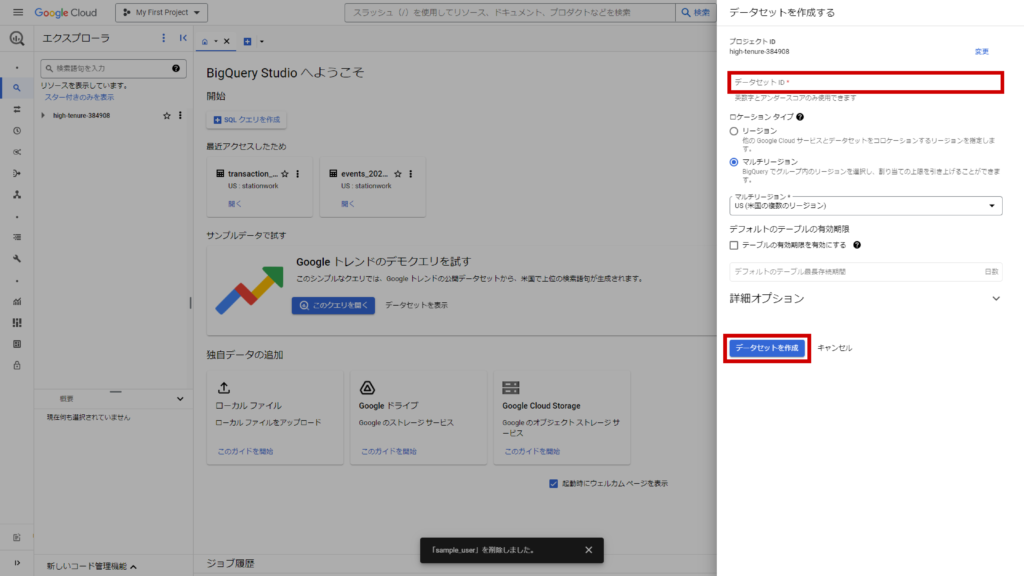
データセット名を入力し、他はデフォルトのままで「データセットを作成」をクリック。
今回はデータセット名をsample_datasetとしました。
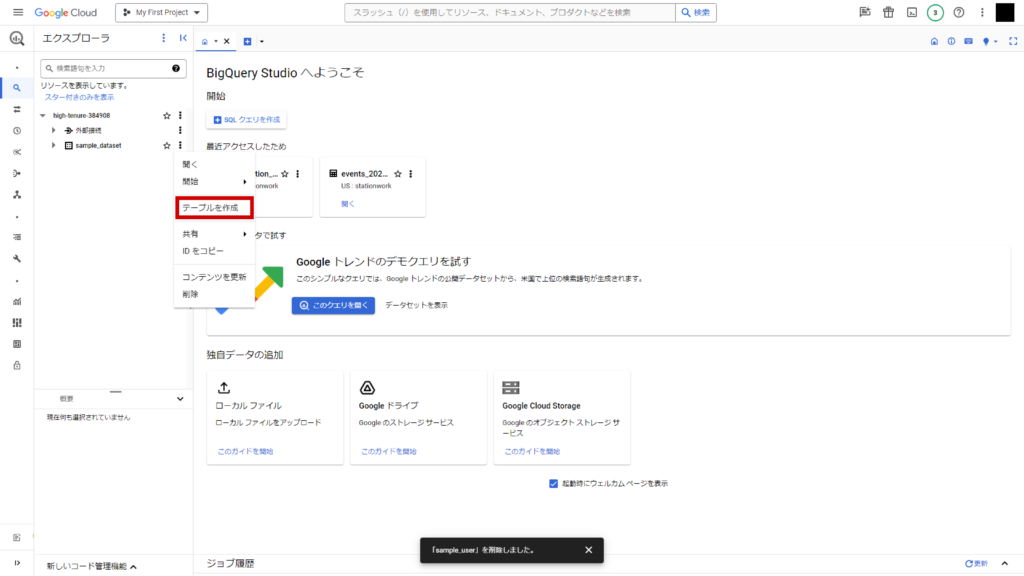
作成されたデータセットの右の三点ボタンから「テーブルを作成」をクリック。
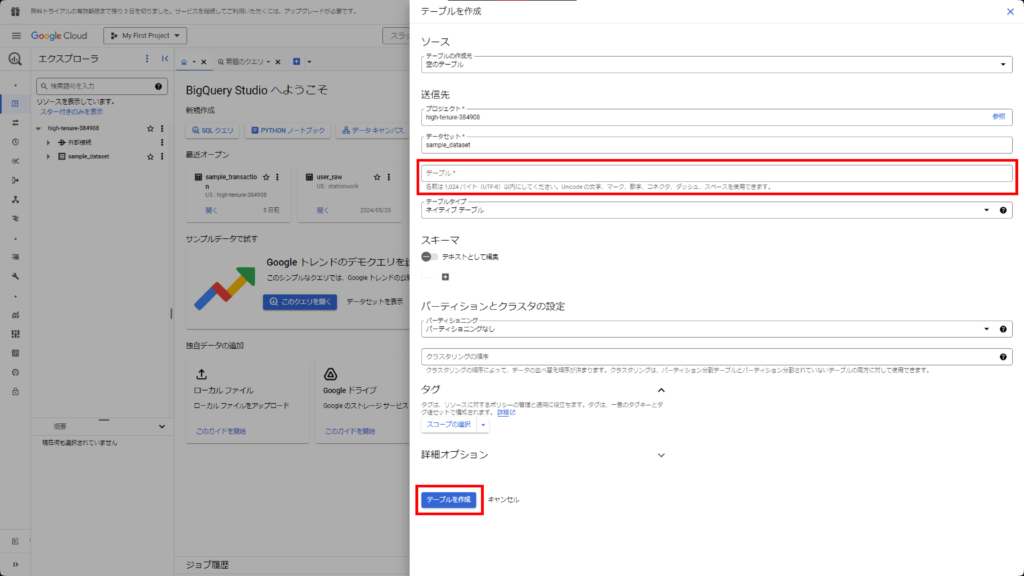
テーブル名をsample_tableに設定し、その他はデフォルトのまま「テーブルを作成」をクリック。
sample_datasetデータセット配下にsample_tableテーブルが作成されました。
BigQueryの設定は以上です。
Cloud Functionsの設定

Cloud Functionsコンソールにアクセスします。
「ファンクションを作成」をクリック。
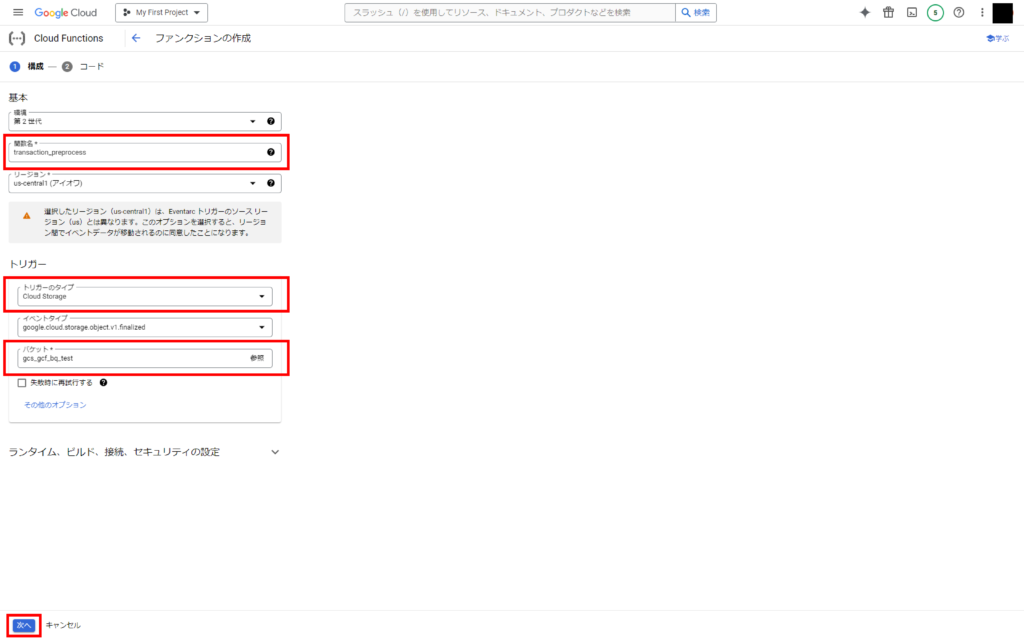
トリガーのタイプを「Cloud Storage」に変更し、バケット欄右の「参照」から、先ほど作成したGCSのバケットを選択します。
これで、GCSへのファイルアップロード完了をトリガーとしてCloud Functionsが起動されるようになります。
設定が完了したら「次へ」をクリック。

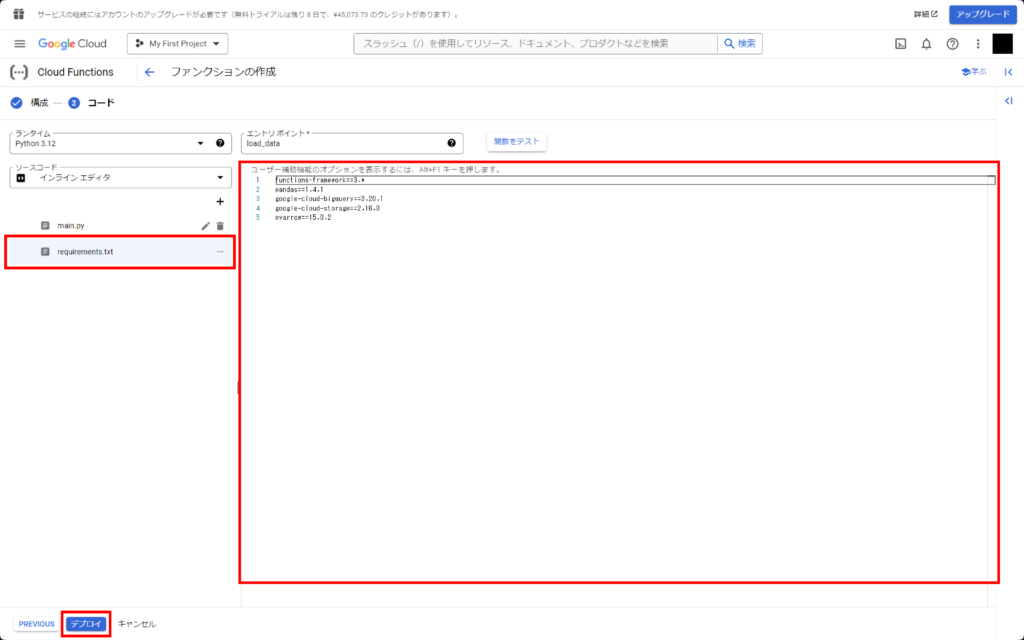
– ランタイム→Python 3.12
– エントリポイント→load_data※
– コード→main.pyとrequirements.txtに下記コードを入力
※エントリポイントは任意の文字列で問題ありませんが、main.py内で定義した関数名と同じにする必要があります。
main.py
import pandas as pd
from io import BytesIO
from google.cloud import bigquery, storage
def load_data(data, context):
content_type = data['contentType']
if content_type != 'text/csv':
print('Not supported file type: {}'.format(content_type))
return
# CSV以外は弾く
project_id = 'プロジェクトID'
bucket_name = data['bucket']
file_name = data['name']
table_id = 'プロジェクトID.sample_dataset.sample_table'
# 「プロジェクトID」は環境に合わせてテキスト変更
bq_client = bigquery.Client(project_id)
gcs_client = storage.Client(project_id)
bucket = gcs_client.get_bucket(bucket_name)
blob = bucket.blob(file_name)
content = blob.download_as_bytes()
df = pd.read_csv(BytesIO(content), dtype={'id': 'object'}, parse_dates=['purchase_dt'])
df['total'] = df['price'] * df['quantity']
# データ加工箇所(新規カラムの追加)
table_object = bigquery.TableReference.from_string(table_id)
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField('id', 'STRING', mode='REQUIRED'),
bigquery.SchemaField('purchase_dt', 'DATETIME', mode='NULLABLE'),
bigquery.SchemaField('product', 'STRING', mode='NULLABLE'),
bigquery.SchemaField('price', 'INT64', mode='NULLABLE'),
bigquery.SchemaField('quantity', 'INT64', mode='NULLABLE'),
bigquery.SchemaField('user', 'STRING', mode='NULLABLE'),
bigquery.SchemaField('total', 'INT64', mode='NULLABLE'),
],
write_disposition='WRITE_APPEND',
)
bq_client.load_table_from_dataframe(df, table_object, job_config=job_config).result()
print("Job finished.")
returnfunctions-framework==3.*
pandas==1.4.1
google-cloud-bigquery==3.20.1
google-cloud-storage==2.16.0
pyarrow==15.0.2全ての入力が完了したら「デプロイ」をクリックします。
デプロイ完了には時間がかかるため気長に待ちましょう。
以上でGCS、Cloud Functions、BigQueryの接続設定が完了しました。
動作確認
CSVファイル
ECサイトの購入データを模したサンプルCSVを2つ使用します。
運用イメージとしては、基幹システムの日次バッチ処理で前日分の購入履歴がCSV出力されており、それらをGCSにアップロードすることでBigQueryへ都度反映し、蓄積するというものです。
id,purchase_dt,product,price,quantity,user
0001,2024/1/1 9:00,商品A,1000,2,JDDL一郎
0002,2024/1/1 12:30,商品A,1000,1,JDDL二郎
0003,2024/1/1 18:00,商品B,300,10,JDDL三郎id,purchase_dt,product,price,quantity,user
0004,2024/1/2 8:00,商品B,300,7,JDDL四郎
0005,2024/1/2 15:00,商品C,1500,2,JDDL五郎
0006,2024/1/2 16:30,商品C,1500,4,JDDL二郎※いずれも文字コードはUTF-8
ファイルアップロード
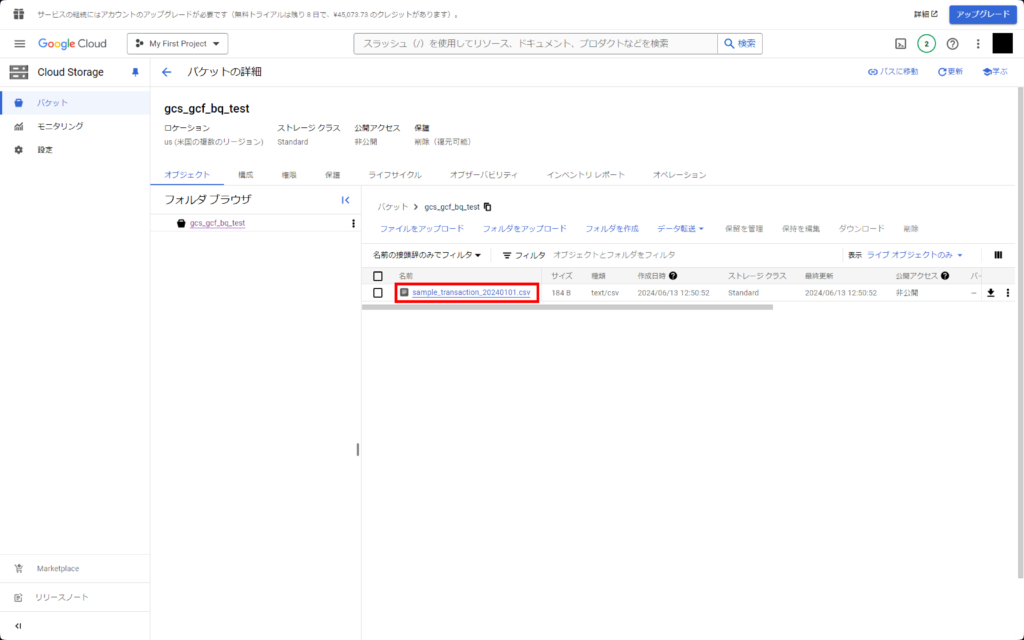
GCSコンソールに移ります。
ドラッグアンドドロップでsample_transaction_20240101.csvファイルをアップロードしましょう。
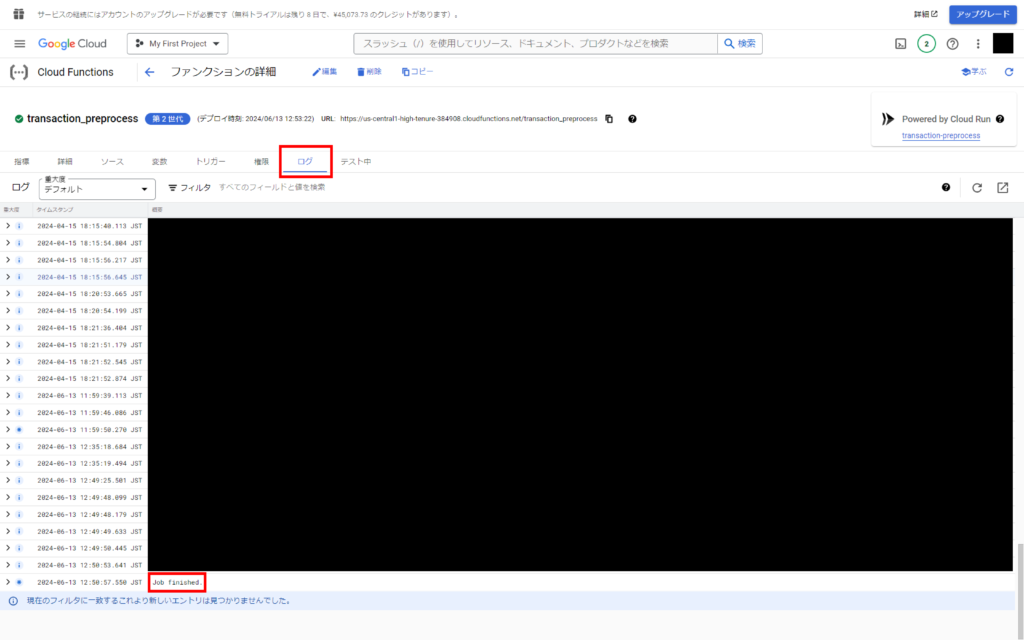
アップロードが完了したら、Cloud Functionsの画面から先ほど作成したファンクションを選択し、「ログ」をクリック。
最下部までスクロールし、ログが更新されて最終的に”Job finished.”と表示されることを確認します。
長くても数分程度でCloud Functionsの動作は終了するはずです。
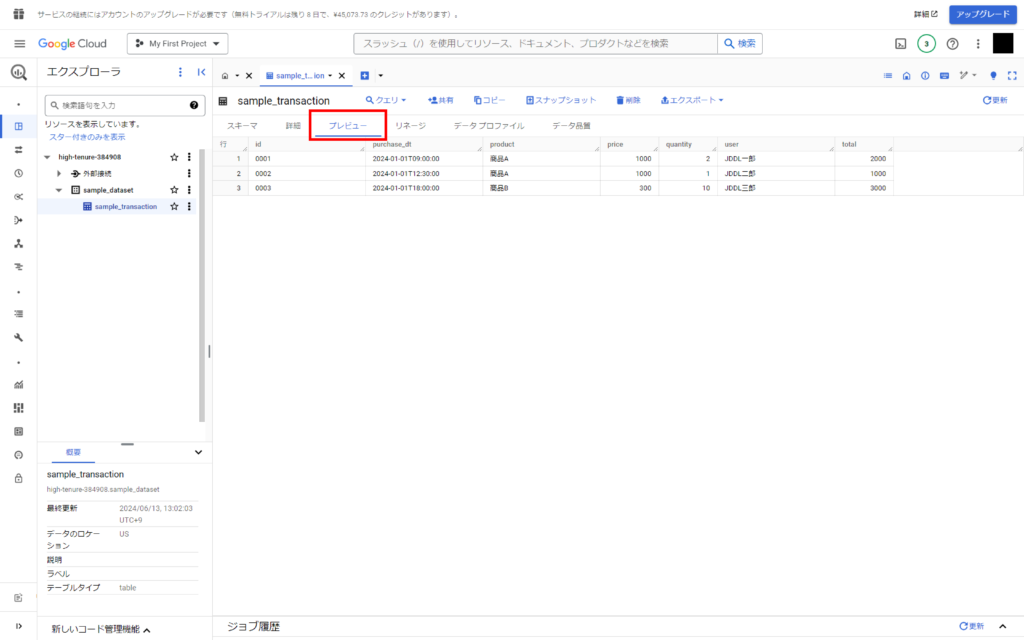
最後にBigQueryにて接続したテーブルの「プレビュー」を表示し、先ほどアップロードしたCSVのデータが反映されていることを確認します。
おめでとうございます!無事にデータの取り込みが完了しました!
もう1つのファイルを再度GCSにアップロードすれば、BigQueryにレコードが追加されて合計6行になることが確認できるかと思います。
【補足】テーブルの作成・更新について
bigquery.LoadJobConfigオブジェクトのwrite_dispositionパラメータを変更することで、テーブルに対する挙動を指定できます。
job_config = bigquery.LoadJobConfig(
schema=[
bigquery.SchemaField('id', 'STRING', mode='REQUIRED'),
bigquery.SchemaField('purchase_dt', 'DATETIME', mode='NULLABLE'),
bigquery.SchemaField('product', 'STRING', mode='NULLABLE'),
bigquery.SchemaField('price', 'INT64', mode='NULLABLE'),
bigquery.SchemaField('quantity', 'INT64', mode='NULLABLE'),
bigquery.SchemaField('user', 'STRING', mode='NULLABLE'),
bigquery.SchemaField('total', 'INT64', mode='NULLABLE'),
],
write_disposition='ここを変更します',
)新規テーブル作成
write_disposition = 'WRITE_EMPTY'指定したテーブルを作成します。
ただし同名のテーブルがすでに存在する場合はエラーとしてプログラムを停止し、テーブルは作成されません。
テーブルの初回作成時などの限定的なシチュエーションで使用します。
SQLのCREATE TABLE IF NOT EXISTSに相当します。
テーブル上書き
write_disposition = 'WRITE_TRUNCATE'指定したテーブル全体を上書きします。
ただし指定したテーブルが存在しない場合はテーブルを作成します。
データの定期更新において、過去分から直近までの全量データが毎回アップロードされるようなシチュエーションの場合はこちらが最適です。
SQLのCREATE OR REPLACE TABLEに相当します。
レコード追加
write_disposition = 'WRITE_APPEND'指定したテーブルに対してレコードを追加します。
ただし指定したテーブルが存在しない場合はエラーとしてプログラムを停止し、テーブルは作成されません。
今回のように直近データのみが毎回アップロードされる場合にはこちらを用いるのが最適です。
SQLのINSERTに相当します。
さいごに
CSVをDB化するにあたって、GCPコンソール上で完結するシンプルな方法をご紹介しました。
今回はCSVファイルのアップロードは手動で行いましたが、GCS APIを用いることでファイルのアップロードからBigQueryへの格納までを完全自動で実装することも可能です。
当社ではデータ分析支援の一環として、GCPを用いたデータ基盤構築も行っております。ご興味のある方はこちらよりお気軽にお問い合わせください。